
CI/CD with Airflow and dbt
The Problem
We want a central location to store and manage data models, and then permit multiple systems to derive their “source of truth” for a model from that repository. A single source of truth allows us to use version control, perform code review, and permits CI/CD for our data models. The benefits include a structured way to change models, and mitigation of error-prone manual schema changes.
But how do you integrate data models in a source control repository into a database, using a CI/CD process?
Our approach integrates DBT, Airflow, and our data model repository. More specifically, our integration requirement is that DBT takes a folder of folders with one schema.yml file in each, and parses that file for configuration detail. We want to derive these schema.yml files from our source of truth when we can.
Implementation
The particular input to DBT we want to generate is the schema.yml file, which includes the table schema, tests against those tables, and some metadata.
Our source of truth files are simple python files that create objects that represent our tables, e.g.
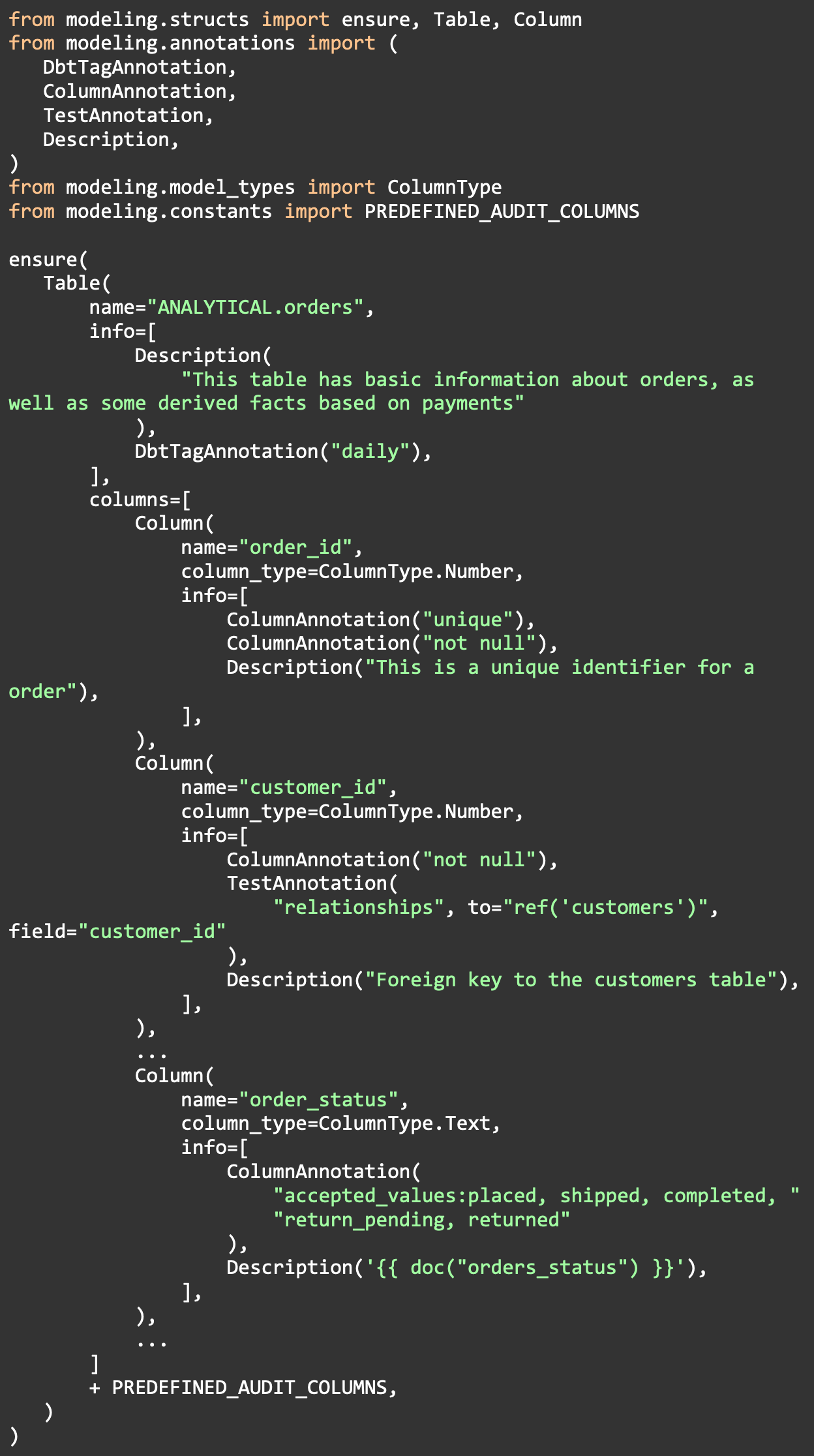
Here’s each table/column above, and the section of the schema.yml it generates:
Python: plugins/models/analytical/orders.py

DBT: plugins/dbt/models/analytical/schema.yml
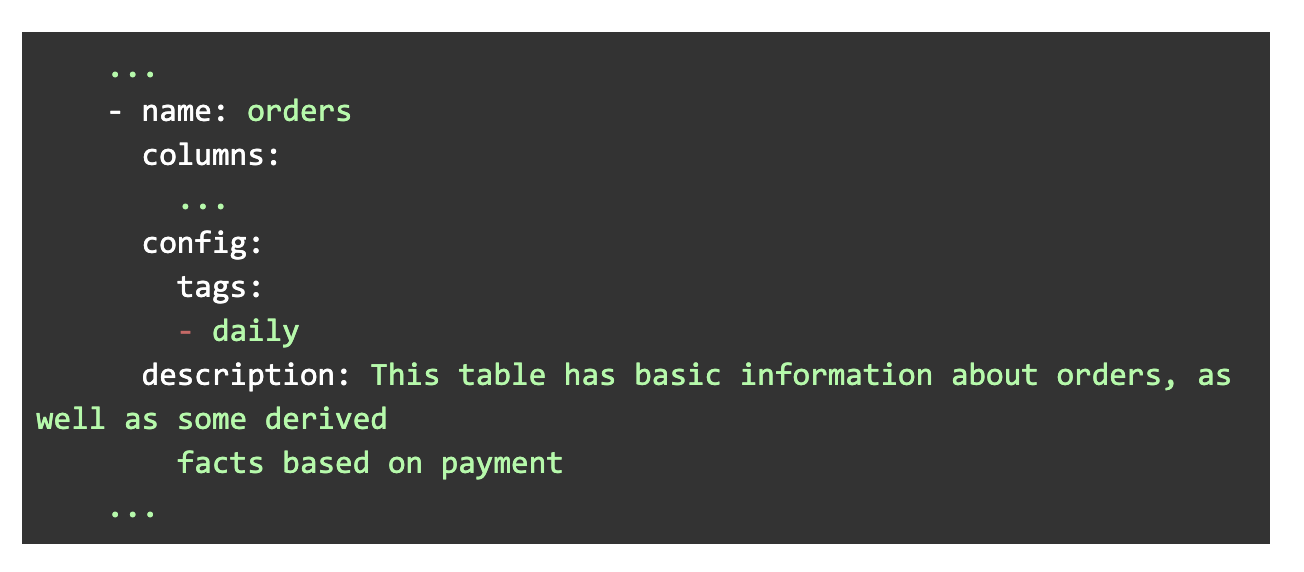
In the above, we see that the DbtTagAnnotation("daily") object causes the string “daily” to be appended in the schema.yml file under the table’s config:{tags:[]} array. A similar thing happens for columns:
Python: plugins/models/analytical/orders.py
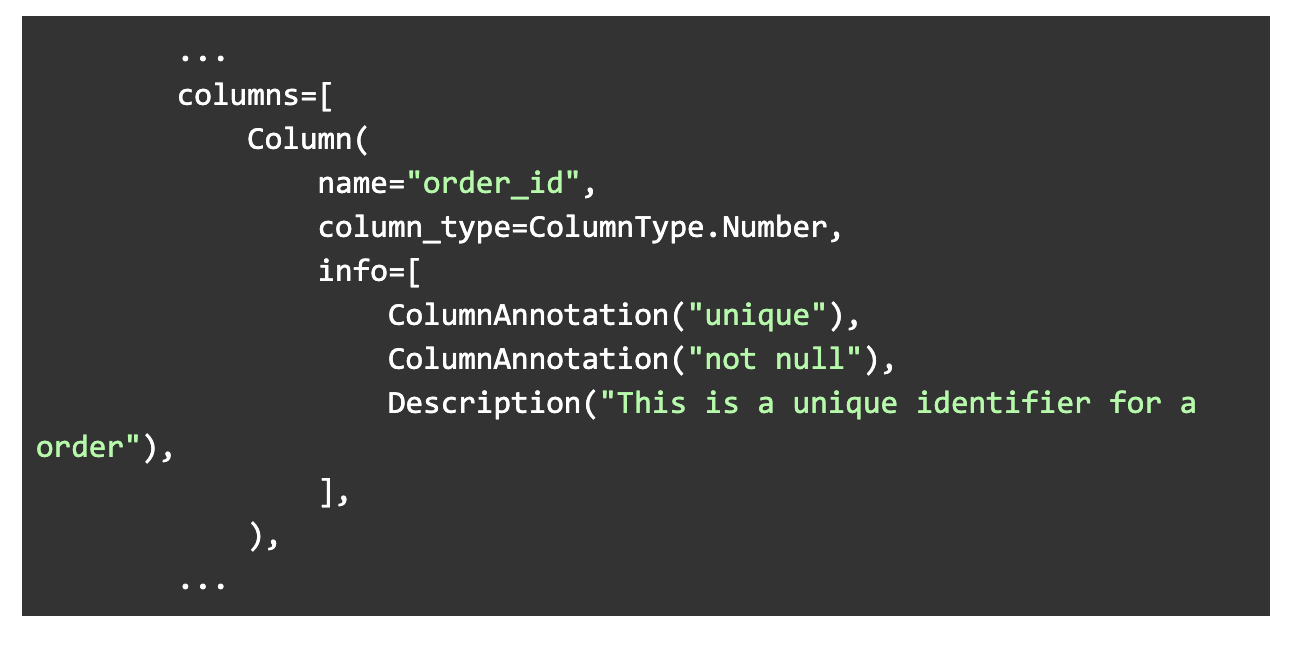
DBT: plugins/dbt/models/analytical/schema.yml

Here, we see the ColumnAnnotation("unique") and ColumnAnnotation("not null") get added to the column’s tests:[] array.
The two tests shown so far are comparatively simple tests. Let’s consider a more complex test:
Python: plugins/models/analytical/orders.py

DBT: plugins/dbt/models/analytical/schema.yml

Here, we have a test with multiple parts, constructed from a different class, TestAnnotation, which receives as arguments a name of a test, and then all the keys and values to the test.
The trick that unites all these annotations is they’re all represented as string-like objects under the hood:

Even the TestAnnotation is just a clever way to map arguments into a string like object:

The benefit of this approach is it simplifies the process from annotations to something else. When we want to render a table’s annotations into things we can put into the schema file, we only need to do a straightforward mapping of strings to collections, and then merge the collections.
All My Best Ideas Are Stolen
For a recent client project, we chose to implement this mapping as a set of regular expressions, that map to functions, that implement the logic that generates the collection. We borrowed an idea from another place that frequently has to map strings that match a pattern to functions, web servers, which usually need to map urls to a particular function to handle the http request.
Web frameworks usually encapsulate this logic in a “Router” class, so we implemented a simple regular expression router to do something similar for our annotation strings. We call the interface “Handlers” but so far they’re all implemented as Routers too. We write handlers like the following:
Python: plugins/modeling/handlers.py
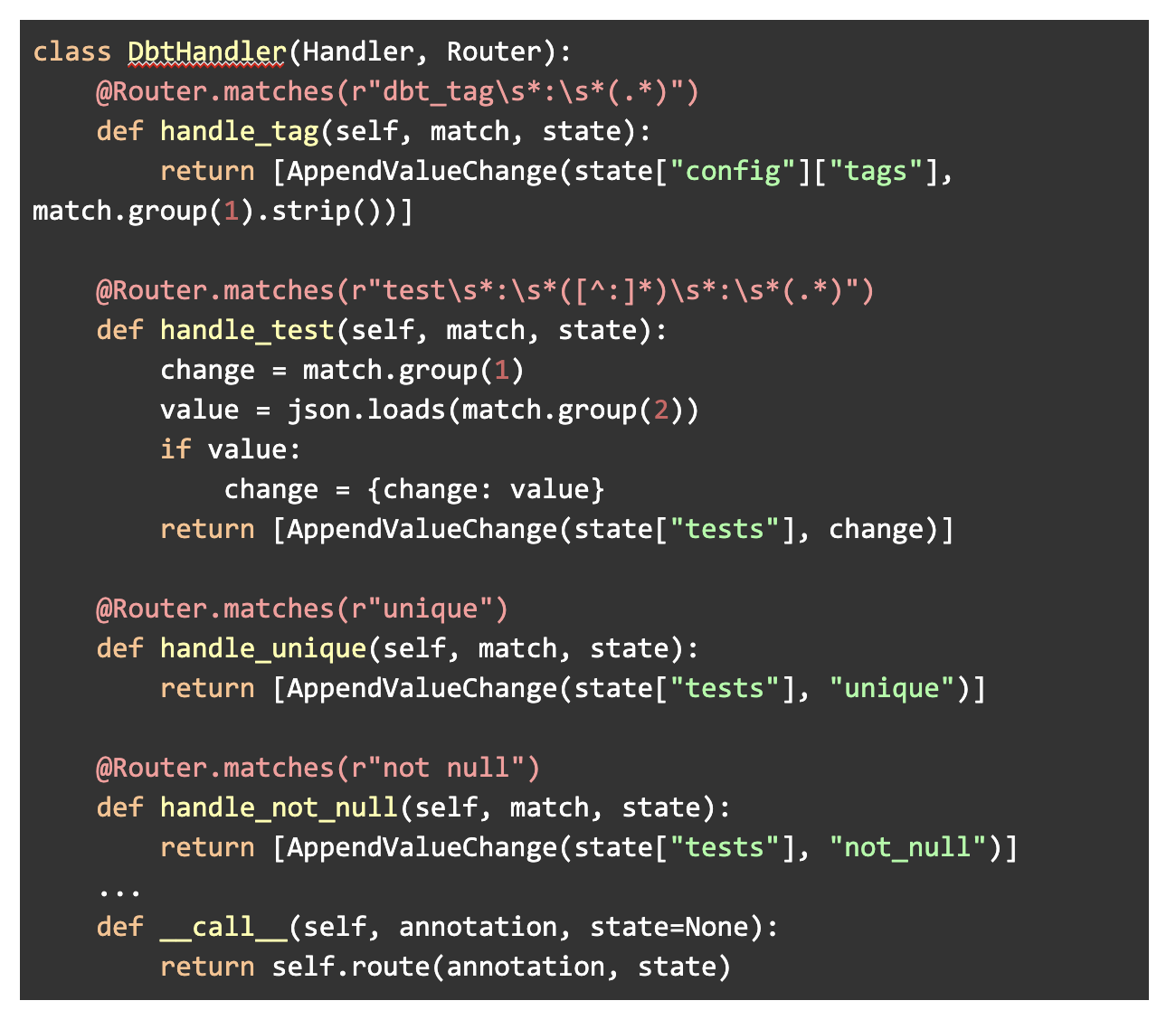
The AppendValueChange class is just a lazy evaluation way to call list.append with the given values.
The router allows us to write regular expressions to handle certain annotation cases, and generally prepending “magic words” like test: or dbt_tag: when constructing the annotation helps us avoid conflicts.
Several open-source projects implement routers for many different reasons. A list is available on the Python Wiki.
Things This Design Did Well:
Extendability
It allowed us to extend this system past just DBT, we use the same system to generate sql statements to send to our database by just implementing a new Handler/Router. The SqlHandler ignores DBT-specific annotations, and any new snowflake-specific annotations that we added didn’t require changes to the DbtHandler.
In addition, the system is flexible enough that the core (Table, Column, Annotation, Router classes) can be lifted from the project and dropped into another project with minimal rewrites, only requiring reimplementation of the Handlers and Change classes to interact with the new project’s external systems. If the new project also uses DBT, the DbtHandler can be used, in effect, we only need to write Handler and Change classes for a system once, and then those classes can be reused in other projects.
Testability
Since tables are just python code, we can write pytest unit tests that get executed by CircleCI that check and report errors about incorrect models.
Things This Design Did Poorly:
It’s not immediately clear whether to use one or multiple annotations
For example, it’s not immediately clear from the syntax if a data modeler needs to use is

or if one annotation with multiple arguments should be used, ex:

What we have so far decides one-or-multiple based on whether the target system considers the metadata to be one-per-object, or multiple-per-object.
Limitations on annotations are not enforced by the syntax
For some annotations it makes no sense to have multiple copies. For example, there’s no meaningful way to have multiple “not null” annotations, either in DBT or SQL.
This system doesn’t force models to have “correct and minimal” Table classes, by syntax. Although they could be caught by a unit test, if knowledge about the annotation exists somewhere in Python. In some cases, for example with TestAnnotation, the json chunk is written out into the schema.yml file and it’s not until DBT is run that errors with the arguments can be detected.
Extension requires knowledge of regular expressions
Regular expressions are hard. Not everyone is familiar and even when you are, they’re sometimes cryptic and hard to parse. Extending handlers requires the developer to be familiar with regular expressions to match their newly added annotation. If we were to rewrite this system, we would consider making annotations into dictionaries instead of strings, and using some sort of dictionary-match router (perhaps taking inspiration from GraphQL).
Conclusion
In this document we outlined a challenge we faced integrating DBT and making it easy to use. We described some of the barriers we faced, and how we solved them in an extensible way that could be reused in other projects. We hope you recall our solution and let it inspire you if you find yourself in a similar situation.